Introduction
I’ve recently completed an online course in R programming and have been weighing its strengths and weaknesses to determine where it would be most advantageous. Traditional workplace programming languages, such as C# and Javascript, seem to always have a place.
It just so happens, a problem arose of needing to query two different MongoDb databases. One database was a production instance, while the other was QA. A report was needed that queried against both databases to compare the contents for missing and invalid documents.
If the goal had been querying over one Mongo instance, an easy solution would be to use an off-the-shelf Mongo client tool. Another possibility is to query a sister) database from within the first. However, since the query spans two databases and contains slightly complicated logic, writing a custom program might better suit the purpose. A custom program also has the advantage of being scheduled to run on a daily basis and is more easily extensible than an inline query.
Where the R Programming Language Excels
Thinking a little more about the problem at hand, there were some features a solution program would need to do. First, it would need to query two MongoDb databases. It would need to cross-reference data from one database against records in the other, by checking against certain columns. It would need to combine some of the columns together to fill in missing data from one and the other. It may also need to perform other table manipulations on rows and columns. Finally, it would need to export the result to a comma-separated (CSV) or Excel file.
These are all features that R is exceedingly good at.
R makes it easy to manipulate tables, matrices, and data frames, seamlessly joining and combining different columns and rows together, and even shaping data. Reading data sources consisting of fixed-width files, comma-separated data, XML, and databases is particularly suitable for R. The data automatically comes in as a matrix, in the form of a data-frame. R also makes it easy to export data to csv. Most of the functionality is native to the R environment.
Why Not Use .NET? Or Node.js? Or ..?
Of course, a console application could be written in C# .NET to query the two databases and perform the cross-validation. Although, this requires creating classes to model the documents, as well as associated plumbing for executing the database queries. A typical example for querying MongoDb with C# .NET appears as follows:
1 | using MongoDB.Bson; |
The above code example demonstrates connecting to a MongoDb instance and searching for a document by IsProfitable. Note, C# requires the creation of an entity class to support the result from the query.
Querying MongoDb with Node.js
Just as easily, a program could be written in node.js to query the MongoDb instance.
1 | var MongoClient = require('mongodb').MongoClient; |
The above code shows a port of the original C# example, written in node.js.
Building a Solution in R
Similar to the above examples, a Mongo library is also available for R. The first step towards querying MongoDb with R is to check for the existence of the library package and install it if necessary. While this step can be skipped during development, it’s handy to include, especially if you will be distributing the R program to others.
We’ll be using the RMongo package.
1 | # Increase JVM memory for large queries. |
The above code checks if the package “RMongo” is present in the list of installed packages within the R environment. If it does not exist, the package is installed. Note, there is an additional line to increase the memory of JVM. This allows R to handle larger query datasets in memory. Finally, we require the RMongo library.
Querying MongoDb in R
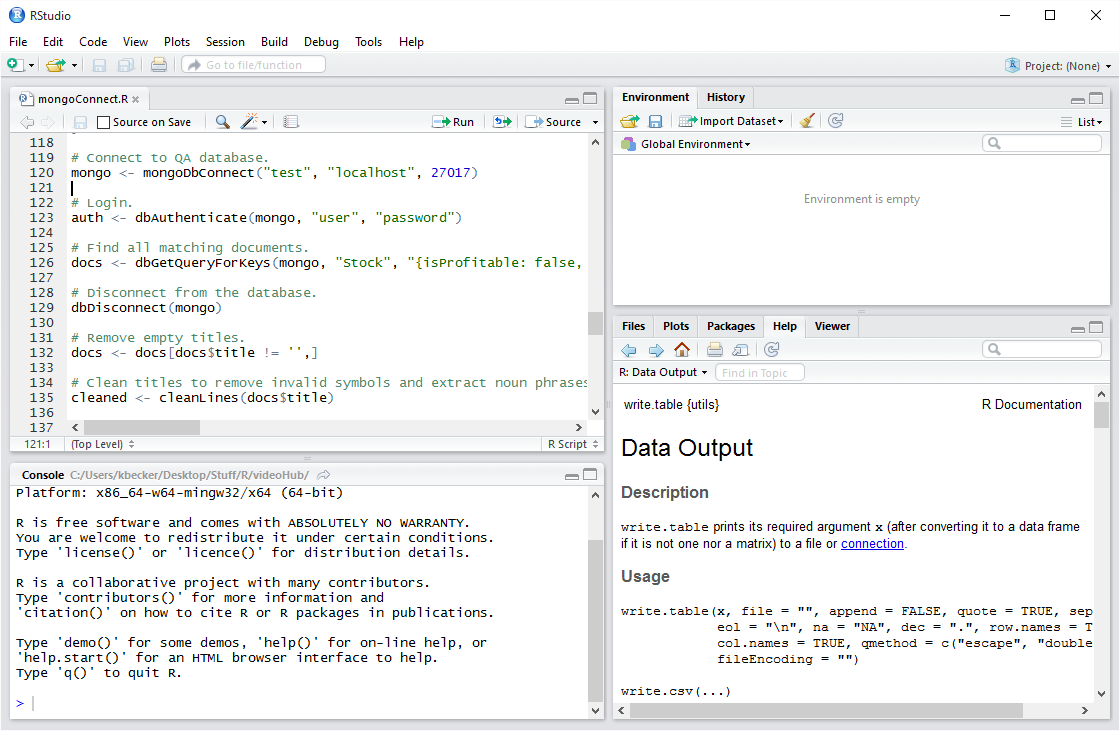
To connect, authenticate, and query a mongo database in R, we can use the following code:
1 | require("RMongo") |
The above code example demonstrates querying a Mongo database with R.
Using the Features of R
With the above query we can read data from a Mongo database. We can repeat the same query for the second database. Once we have the data in memory, we can begin taking advantage of some of the power features in R to tweak the resulting data set to our liking. First, we’ll want to format a date column as an actual Date, rather than a string. This will allow sorting the column in Excel. We’ll also want to convert a boolean column to the “logical” data type, rather than string.
1 | # Set date format for parsing mongo datetime fields. |
The above code transforms two columns in the resulting data.frame to be of type “logical” (boolean) and POSIXlt (datetime).
Finding Missing Documents in Two Tables with R
After querying the second database, we can now check for missing documents in the two databases.
1 | # Find stories in the production database that are missing in the QA database. |
Saving the Results to a CSV File
After manipulation of the data is completed, we can save the result to a CSV file, compatible with Excel, by using the following code:
1 | # Sort the data sets by startDate. |
Conclusion
There are often multiple ways to implement a solution for a problem, typically solvable by a number of different programming languages. A good solution is, of course, one that works. However, the best solution is one that is also easy to understand and maintain. When the task involves manipulating and transforming large data sets, a solution built upon R can offer a quick and powerful result.
About the Author
This article was written by Kory Becker, software developer and architect, skilled in a range of technologies, including web application development, machine learning, artificial intelligence, and data science.
Sponsor Me